- categories: Data Science, Architecture, Deep Learning
Definition:
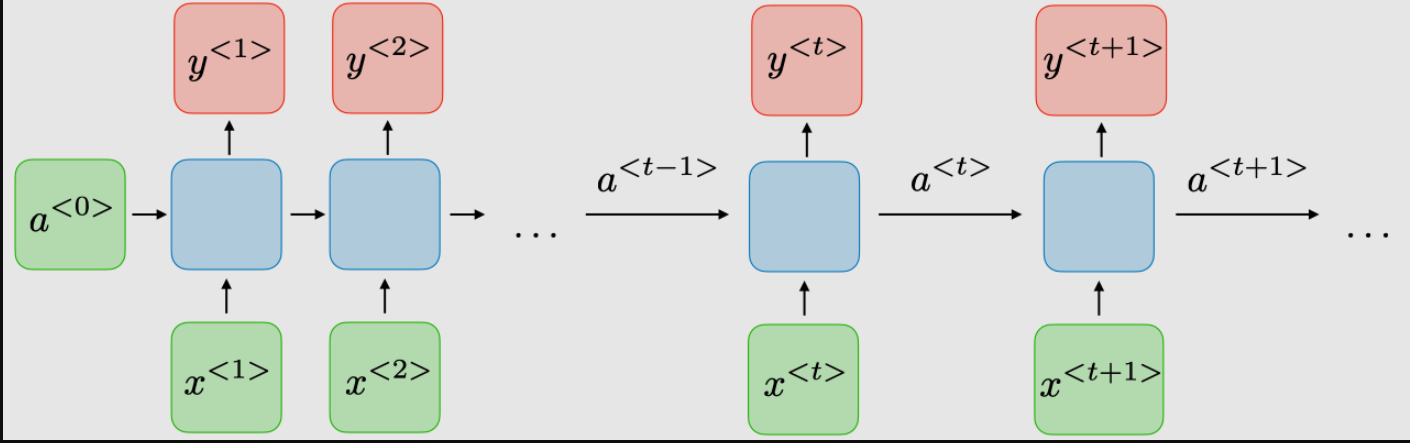
Recurrent Neural Networks (RNNs) are a class of neural networks designed for processing sequential data. Unlike feedforward networks, RNNs maintain a hidden state that captures information about previous inputs, enabling them to model temporal dependencies. This makes RNNs well-suited for tasks such as natural language processing, speech recognition, and time-series forecasting.
Key Idea
RNNs process sequences one step at a time, maintaining a hidden state that is updated recurrently. At each time step , the hidden state depends on the current input and the previous hidden state .
Mathematical Formulation
-
Hidden State Update:
where:- : Hidden state at time .
- : Input at time .
- : Recurrent weight matrix (hidden-to-hidden).
- : Input weight matrix (input-to-hidden).
- : Bias term.
- : Activation function (e.g., tanh or ReLU).
-
Output:
where:- : Output at time .
- : Output weight matrix (hidden-to-output).
- : Output activation function (e.g., softmax for classification).
Backpropagation Through Time (BPTT)
RNNs are trained using a variation of Backpropagation Algorithm called Backpropagation Through Time (BPTT). This involves unrolling the RNN across time steps and computing gradients for each time step.
Limitations of Vanilla RNNs
-
Difficulty Capturing Long-Term Dependencies:
- Vanilla RNNs struggle with sequences where long-term context is critical.
-
Vanishing and Exploding Gradient Problem:
- As gradients are propagated through many time steps, they tend to vanish or explode, making training unstable.
-
Sequential Processing:
- Cannot parallelize across time steps, leading to slower training compared to feedforward models.
Variants of RNNs
-
Long Short-Term Memory (LSTM):
- Introduces memory cells and gating mechanisms to mitigate vanishing gradients and better capture long-term dependencies.
- Components: Forget gate, input gate, output gate.
-
- A simplified version of LSTM with fewer parameters.
- Combines the forget and input gates into a single update gate.
-
Bidirectional RNNs:
- Processes the sequence in both forward and backward directions, capturing context from both past and future.
-
Sequence-to-Sequence (Seq2Seq) Models:
- Consists of an encoder RNN and a decoder RNN.
- Used for tasks like machine translation and text summarization.
Implementation in PyTorch
import torch
import torch.nn as nn
# Define an RNN model
class RNNModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers):
super(RNNModel, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# RNN layer
out, hidden = self.rnn(x) # `out` contains outputs at all time steps
# Fully connected layer (use the last time step output)
out = self.fc(out[:, -1, :])
return out
# Hyperparameters
input_size = 10 # Number of input features
hidden_size = 20 # Number of hidden units
output_size = 1 # Output dimension
num_layers = 2 # Number of RNN layers
# Instantiate the model
model = RNNModel(input_size, hidden_size, output_size, num_layers)
# Example input
x = torch.randn(5, 50, input_size) # Batch of 5 sequences, each of length 50
output = model(x)
print(output.shape) # Output shape: [5, 1]Comparison with LSTM and GRU
| Feature | RNN | LSTM | GRU |
|---|---|---|---|
| Handles Long-Term Dependencies | Poor | Excellent | Good |
| Complexity | Low | High | Moderate |
| Parameters | Fewer | More | Fewer than LSTM |
| Training Stability | Unstable (vanishing gradients) | Stable | Stable |
Advantages
-
Captures Sequential Information:
- Maintains hidden states, allowing modeling of temporal patterns.
-
Parameter Sharing:
- Uses the same weights across time steps, reducing model complexity.
-
Flexibility:
- Can process sequences of varying lengths.
Disadvantages
-
Difficulty with Long Sequences:
- Vanilla RNNs struggle with long-term dependencies.
-
Sequential Processing:
- Slower training compared to parallelizable architectures like Transformers.
-
Gradient Issues:
- Prone to vanishing or exploding gradients.
Recent Alternatives
-
- Allow the model to focus on relevant parts of the sequence.