- categories: Data Science, Architecture, Deep Learning
Definition:
The Gated Recurrent Unit (GRU) is a type of Recurrent Neural Network architecture introduced as a simplified alternative to Long Short-Term Memory (LSTM). It uses gating mechanisms to control the flow of information, allowing the network to capture dependencies over long sequences while being computationally more efficient than LSTM.
Key Features of GRU
-
Simplified Gating Mechanisms:
- GRUs combine the forget and input gates of LSTMs into a single update gate.
- GRUs have fewer parameters than LSTMs, making them computationally lighter.
-
Memory Management:
- GRUs maintain a hidden state that directly serves as both the memory and output at each time step.
- They do not have a separate cell state like LSTMs.
GRU Architecture
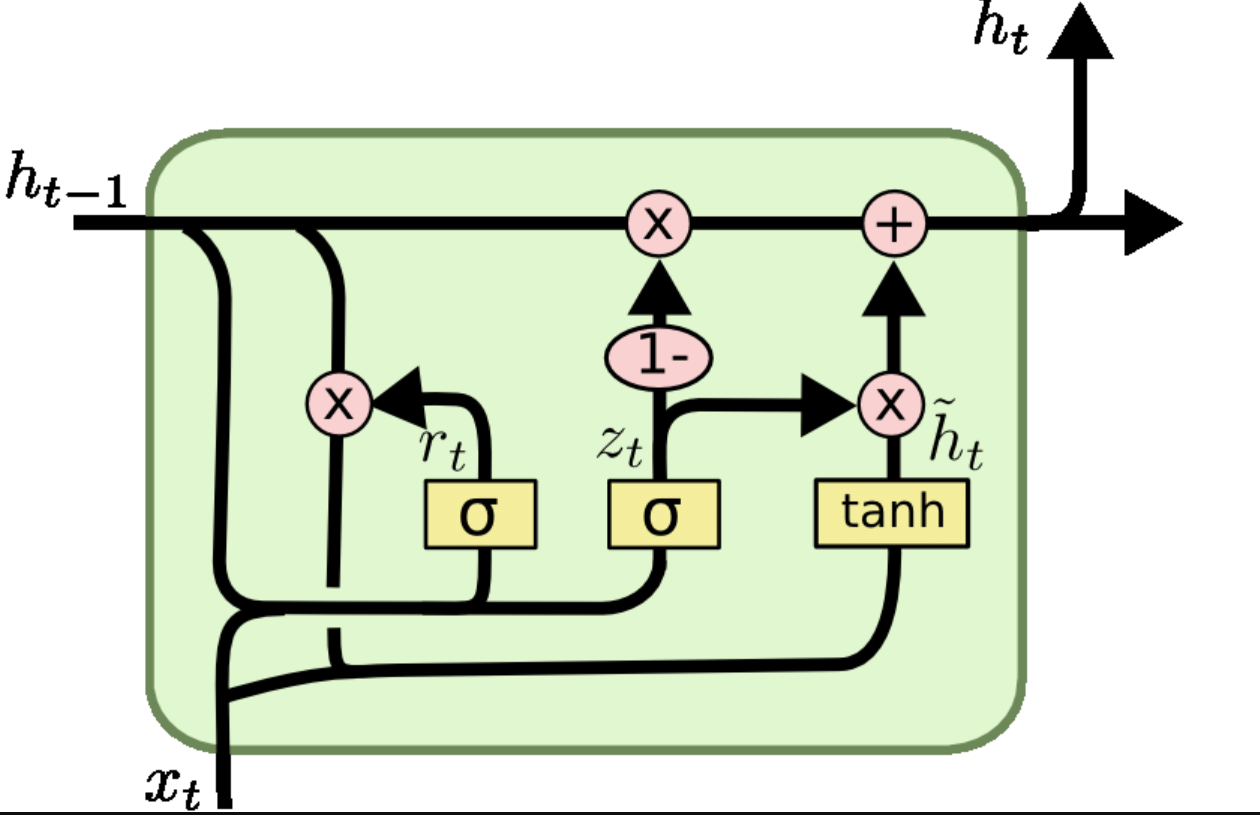
A GRU cell consists of the following components:
-
Reset Gate ():
- Controls how much of the past information to forget.
-
Update Gate ():
- Controls how much of the past information to retain and how much of the new information to use.
-
Candidate Hidden State ():
- Represents the potential update to the hidden state, incorporating both current input and past information.
-
Hidden State ():
- The final hidden state, computed as a combination of the previous hidden state and the candidate hidden state.
Mathematical Formulation
Let:
- : Input at time step .
- : Hidden state at the previous time step.
- : Weight matrices.
- : Bias terms.
1. Reset Gate:
Controls the contribution of the previous hidden state:
2. Update Gate:
Determines how much of the past and new information to combine:
3. Candidate Hidden State:
Computes the potential update for the hidden state:
4. Hidden State:
Blends the previous hidden state and the candidate hidden state:
Here, is the sigmoid activation function, is the hyperbolic tangent, and denotes elementwise multiplication.
Comparison with LSTM
| Feature | GRU | LSTM |
|---|---|---|
| Gating Mechanisms | Reset and update gates | Forget, input, output, and cell gates |
| Memory Management | Hidden state only | Separate cell state and hidden state |
| Number of Parameters | Fewer (more efficient) | More (greater capacity) |
| Computation Complexity | Lower | Higher |
| Performance on Long Sequences | Good, but may struggle in extreme cases | Excellent for long dependencies |
Advantages of GRU
-
Simplicity:
- Fewer gates and parameters make GRUs easier to train compared to LSTMs.
-
Efficiency:
- Faster training and inference due to reduced computational overhead.
-
Performance:
- Matches or exceeds LSTM performance on many tasks, especially with smaller datasets or fewer resources.
Disadvantages of GRU
-
Less Expressive Power:
- The combined reset-update mechanism may lack the flexibility of LSTM gates in capturing complex dependencies.
-
Limited Long-Term Memory:
- While GRUs perform well on moderate-length sequences, LSTMs may outperform them on tasks requiring very long-term dependencies.
Applications of GRU
-
Natural Language Processing (NLP):
- Sentiment analysis.
- Machine translation.
- Text summarization.
-
Speech Processing:
- Audio-to-text transcription.
- Speaker recognition.
-
Time-Series Analysis:
- Stock price prediction.
- Energy demand forecasting.
-
Video Analysis:
- Action recognition.
Implementation in PyTorch
import torch
import torch.nn as nn
# Define a GRU model
class GRUModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers):
super(GRUModel, self).__init__()
self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# GRU layer
out, hidden = self.gru(x) # `out` contains outputs at all time steps
# Fully connected layer (use the last time step output)
out = self.fc(out[:, -1, :])
return out
# Hyperparameters
input_size = 10 # Number of input features
hidden_size = 20 # Number of hidden units
output_size = 1 # Output dimension
num_layers = 2 # Number of GRU layers
# Instantiate the model
model = GRUModel(input_size, hidden_size, output_size, num_layers)
# Example input
x = torch.randn(5, 50, input_size) # Batch of 5 sequences, each of length 50
output = model(x)
print(output.shape) # Output shape: [5, 1]Key Intuition
- Reset Gate (): Controls how much of the past hidden state to “forget.”
- Update Gate (): Determines the balance between retaining past information and adding new information.
Together, these gates ensure that the GRU can effectively learn dependencies across different time scales without the complexity of an LSTM.
Comparison with Other Architectures
| Feature | Vanilla RNN | GRU | LSTM | |
|---|---|---|---|---|
| Long-Term Dependencies | Poor | Good | Excellent | |
| Number of Gates | None | 2 (reset, update) | 3 (forget, input, output) | |
| Parameters | Few | Moderate | Many | |
| Computational Efficiency | High | Moderate | Lower | |
| Use Cases | Simple tasks | Moderate-length tasks | Long-term dependencies |
Conclusion
The GRU strikes a balance between simplicity and performance, offering a computationally efficient alternative to LSTMs while retaining the ability to model long-term dependencies in sequential data. It is widely used in tasks where the complexity of LSTMs is not warranted or where computational resources are limited.