- categories: Data Science, Paper, Transformers
https://arxiv.org/abs/1706.03762
Key Concepts:
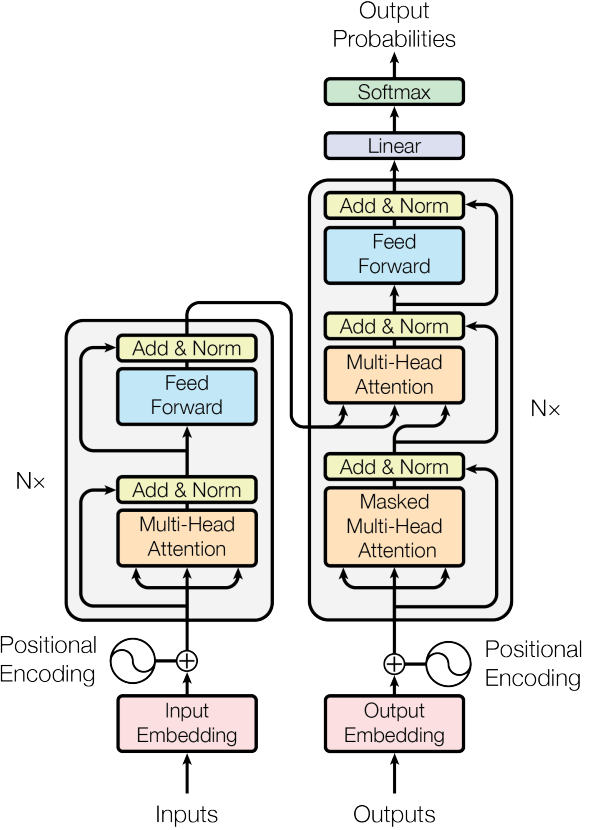
- Transformer Architecture:
- Composed of an encoder-decoder structure.
- The encoder processes the input sequence, and the decoder generates the output sequence.
- Self-Attention:
- A mechanism to compute a representation of each word in a sequence in relation to every other word, allowing the model to focus on relevant parts of the input.
- Multi-Head Attention:
- Extends self-attention by using multiple attention heads, each focusing on different aspects of the input sequence.
- Positional Encoding:
- Introduced to incorporate information about the order of words in a sequence since the architecture itself does not inherently process sequential information.
- Feed-Forward Neural Network:
- Each position in the sequence is processed by a fully connected feed-forward network after the attention mechanism.
- Residual Connections and Layer Normalization:
- Used to stabilize training and improve gradient flow.
- Efficiency:
- By removing recurrence, Transformers processes sequences in parallel, leading to significant improvements in computational efficiency compared to RNNs or LSTMs.
Advantages:
- Parallelization: Unlike RNNs, Transformers can process an entire sequence simultaneously.
- Scalability: Better suited for training on large datasets.
- Flexibility: Works well across a variety of tasks beyond NLP, including vision and time-series analysis.
Visual Explanations
- https://www.youtube.com/watch?v=-QH8fRhqFHM
- https://jalammar.github.io/illustrated-transformer/
- https://colab.research.google.com/github/tensorflow/tensor2tensor/blob/master/tensor2tensor/notebooks/hello_t2t.ipynb#scrollTo=X3mkIEcbfiTP
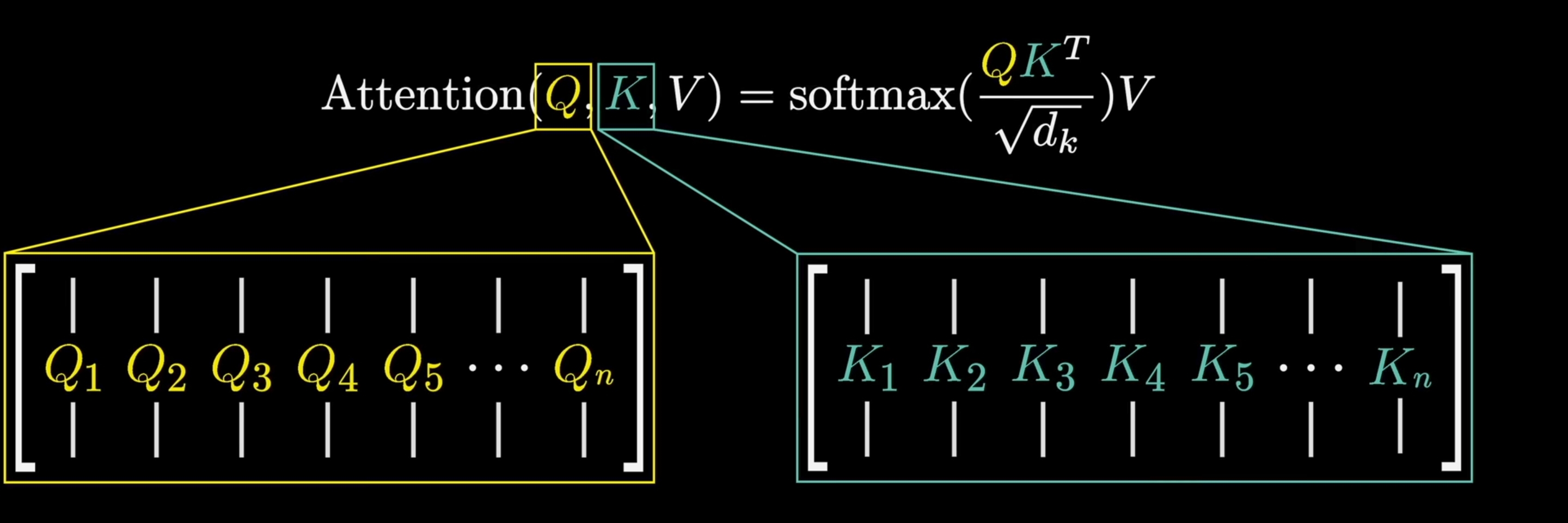
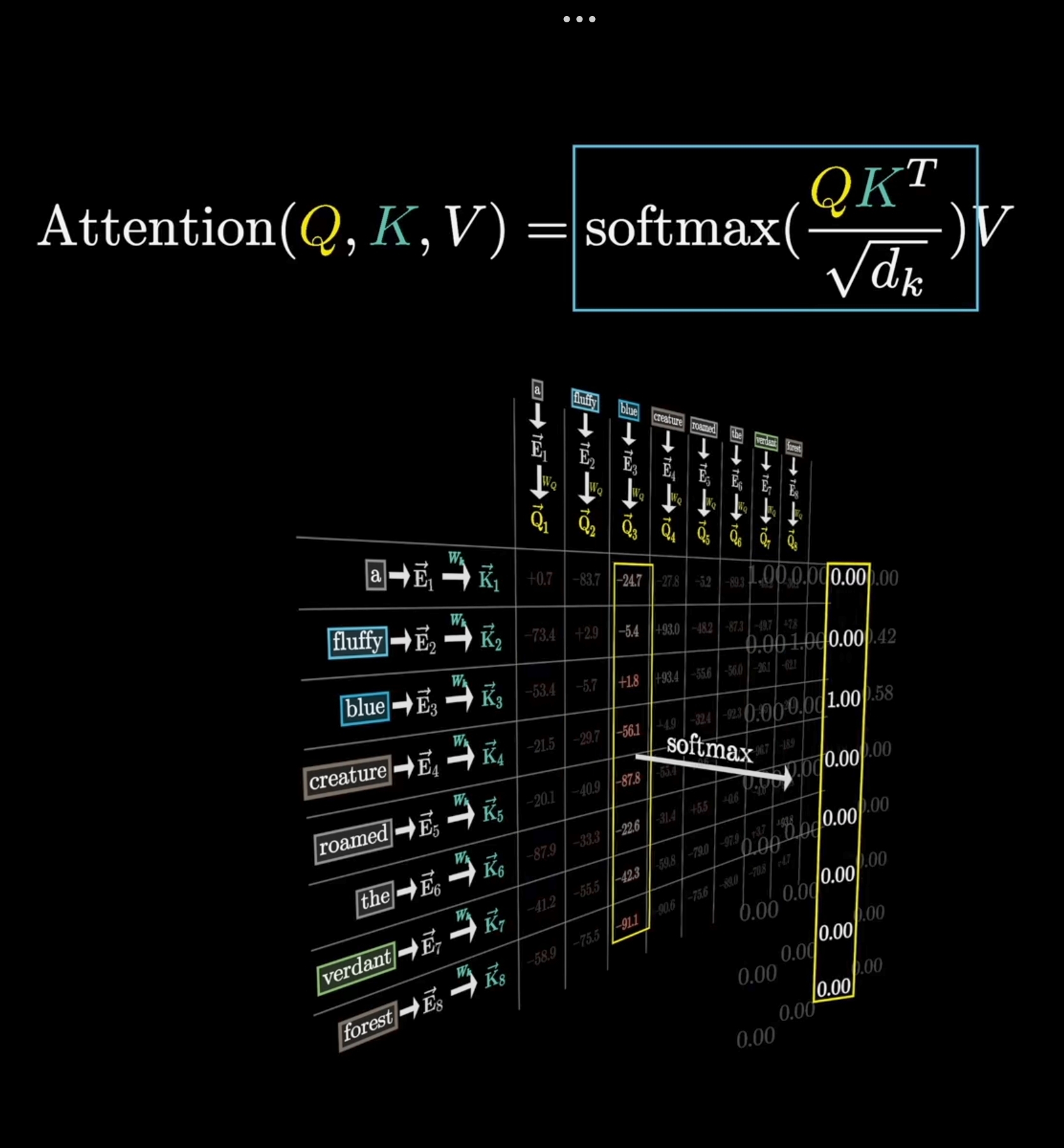
Multihead Attention Visualization
![]()
implementation in Pytorch
https://nlp.seas.harvard.edu/2018/04/03/attention.html
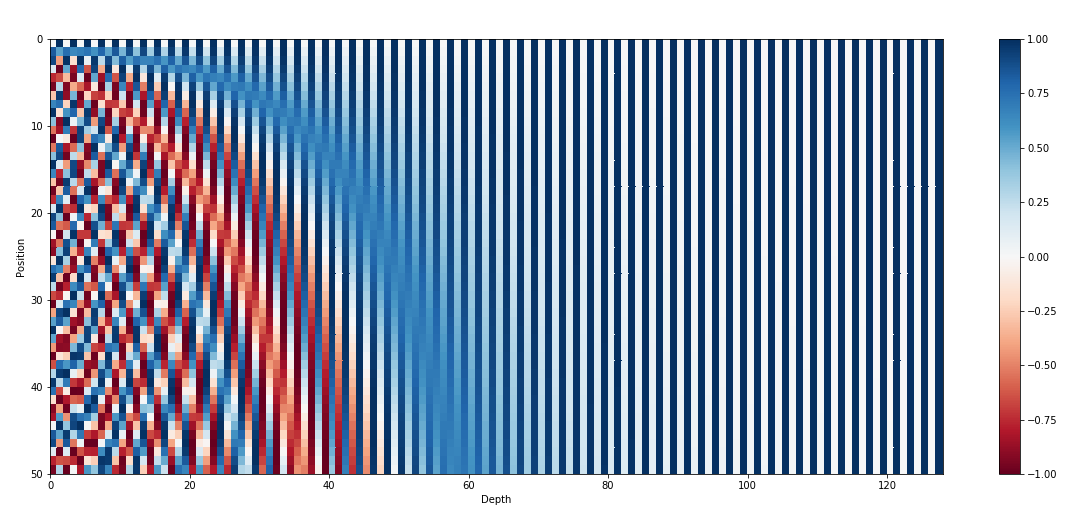
Why Use Sine and Cosine in Positional Encoding?
Transformers do not inherently understand sequence order since they lack a recurrent structure. To address this, positional encodings are added to input embeddings to encode positional information.
For deeper dive see https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
The 128-dimensional positonal encoding for a sentence with the maximum lenght of 50. Each row represents the embedding vector